
Docs: FAQ
About #
Who are you? #
My name is Michael Winters, and I’m a Fedora Contributor. (“Hi, Michael.”) You can find me on
Fedora Matrix in the Data WG room (#data:fedoraproject.org) as @mwinters.
My career is in Staff SRE and Enterprise Architecture, but I’ve always strangely enjoyed ETL projects. I’m now wading into data infra / engineering / architecture to help the Fedora “Community Operations” team (“CommOps”) achieve their goals. For more info, see: Goals on the home page.
I’m also currently seeking employment, if you happen to know of any. I’m specifically seeking that which aligns with my values.
Policy #
Privacy #
Are you evil? Why are you publishing all this data about people? #
Everything on Hatlas has already been made publicly available by Fedora for many years (*see below), albeit via huge database backup files and inconvenient APIs. Hatlas merely eliminates the step of “stand up your own Postgres and restore a database backup” in order to simplify access for CommOps analysts and to enable us to understand our community and improve it. (See: our Goals on the home page. And if you doubt our intentions, please come visit us in the Data WG Matrix channel to see the work that our Fedoran analysts are doing with this data.)
This simplified access also allows those who are privacy-conscious to easily discover what data is being published about them, and therefore to understand what data other systems / companies that ingest Fedora data (who probably aren’t in Fedora Matrix or open about their operations) may possess about your Fedora activities.
You’re welcome!
*Upstream data locations:
- Fedora Infrastructure DB Dumps
- Datagrepper (Searches the Datanommer dataset.)
How is my data protected? #
We expect all who access Hatlas to agree to the Data Usage Guidelines and the Licensing below. In the near future we plan to enforce agreement to this policy before granting access. (See: Contributing: OAuth)
Why didn’t you wait until this data is behind a login? #
The upstream Fedora data sources are not behind a login. It’s certainly a desired improvement.
Removal #
If you feel strongly that you want to be erased from Fedora datasets, please work through the existing Fedora Personal Data Removal (“PDR”) request process. Hatlas is downstream of Fedora, and deleting data from Hatlas does not remove your data from being publicly accessible via Fedora endpoints. If you have gone through that process and still see your data here after a reasonable amount of time, please contact me directly.
If you find some concerning PII in the data that you believe shouldn’t be there at all (or any security issues), please email me directly – my email is in the site footer. But again, all data sources are upstream of Hatlas, so while I can delete it from Hatlas immediately, getting it permanently solved will require me to route this upstream (which I’m happy to do).
Hatlas website data #
We are logging portions of web traffic, with the intent of understanding usage patterns and how they correlate to server load for the purpose of delivering this site. We intend to eventually share these publicly, but if/when that happens they will be pseudonymized first – meaning, IP addresses and other identifiers will be redacted.
Licensing #
The Fedora data licensing situation is a bit murky. There does not seem to be any license explicitly attached to the Fedora datasets. We have open questions out to the Fedora legal team to try to get some concrete answers.
The general consensus amongst the Fedora Council is that this data is likely made available under an extremely permissive license such as PDDL. If you require strong licensing assurances, you might wish to wait until we’ve received that clarity.
Hatlas data is made available under CC BY-NC-SA 4.0.
The Hatlas website is © 2025 Michael Winters and licensed under CC BY-NC-SA 4.0.
Tech #
What’s a Data Lakehouse? Iceberg? Polaris? #
- A Lakehouse allows us to take data that would normally live in many different places and formats and bring it together under one roof where we can analyze it.
- Iceberg is a way to inventory (aka “catalog”) the data that you have, so that your “query
engine” (e.g. JupyterLab) knows what’s in your lakehouse and how to access it.
- The Apache Iceberg project both develops a general standard called “Iceberg” and provides a set of implementations of that standard, also called “Iceberg”. It’s great.
- Polaris is one implementation of the Iceberg standard amongst many. We chose it because it is emerging as a leader in business settings, where they have requirements similar to ours such as eventually integrating with the Fedora Accounts System (“FAS”).
How does a Lakehouse compare to a Database? #
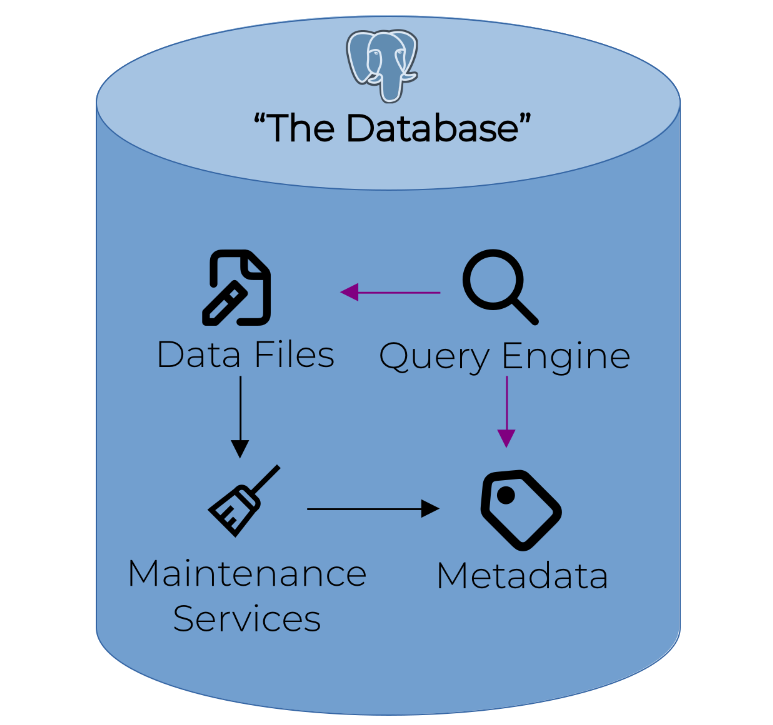
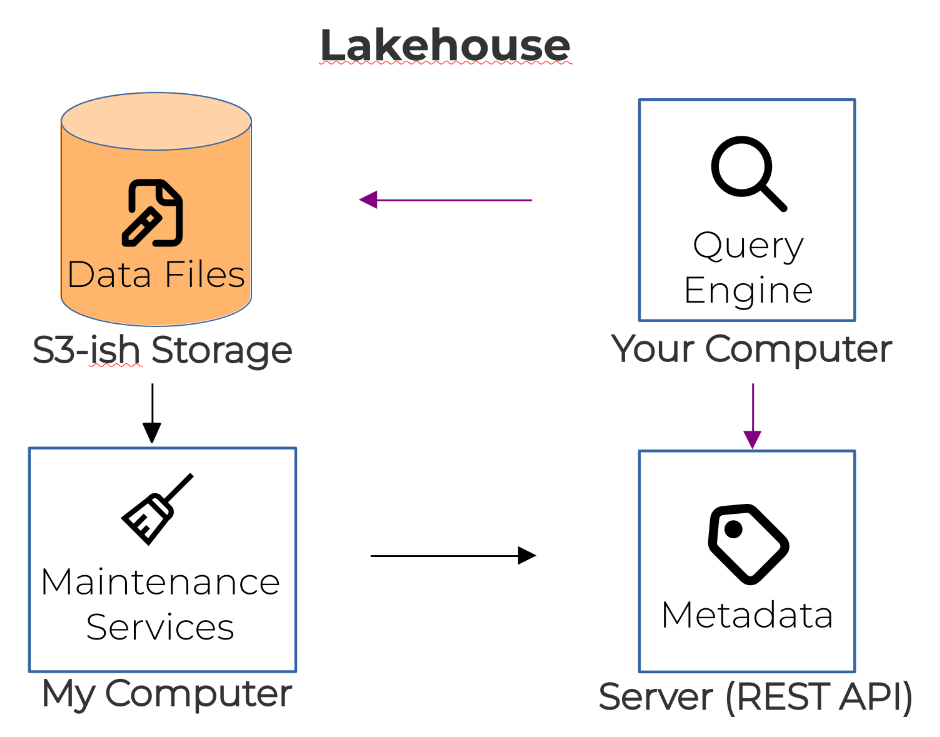
Why aren’t you running this on Fedora Infra? #
- Because it’s hard! A lot harder than just spinning up a VPS. It’s planned, but for details see: Contributing (Polaris Fedora).
- Some questions about what sort of infra we’ll need can only be answered with a POC, e.g. how much compute we will require, or the best way to manage the database.
- Polaris is still evolving rapidly and I’m still new to it. I don’t have confidence yet that I can deliver anything reliable. If Hatlas goes down, I don’t want anyone coming to the Fedora Infrastructure room to ask for help, as those folks already have their hands full fighting off waves of AI scraper zombies.
- There could be lingering data issues, e.g. some PII in there that we don’t know about yet. In an emergency situation, I’d feel much more ok with “pulling the plug” on a personal project until things are resolved, rather than disrupting something official. (I also don’t even know that I’d be able to unilaterally pull the plug within Fedora.)
What version of Polaris are you running? #
Last Updated: 2025-11-09
We are running a recent commit from the main branch, as support for non-AWS S3 (specifically, S3
without STS) only landed a few weeks ago. Technically this version is called
1.3.0-incubating-SNAPSHOT.
We are extremely early adopters, and are working with the Polaris community to provide feedback. Some turbulence is anticipated. Please fasten your seat belts.
What is your architecture / roadmap? #
See: Contributing (Infrastructure).
Where is your source code? #
I don’t have any yet! Hatlas went online the first time my “Hello World” test completed successfully.
I’ve been too busy participating in the privacy conversations around Hatlas to turn my notes.txt and atuin history into code, but it will happen in the near future. The target architecture is to get everything into Airflow (or equivalent) so this will happen asap!
The source code for this website is available here.